
Nowadays, most people are already familiar with AI and its capabilities. AI is able to process questions, understand context, generate responses that can be perceived by humans, and even perform much more complex reasoning that once required human expertise. Last week, I got a request from my family member to do a research regarding an investment topic(not crypto related 😂). He mentions that to research and understand more, you can check from either ChatGPT, Gemini or Perplexity.
At that moment, I was super impressed that even the older generations knew about Perplexity. Then at that moment I knew, these generations are already able to accept the existence of AI in their life.
However, for the next level, understanding Agentic AI requires a little bit more understanding on the technicalities and terminologies. This article is to cover most of the terminologies surrounding Agentic AI.
Agents
Agents, specifically AI Agents, are a type of AI that is able to run in a workflow to complete tasks. AI Agents need to understand the goals and call LLMs in order to do reasoning. It also able to call Tools, ie external API calls, querying databases, running codes, and etc.
In order to function properly, similar to humans, AI Agents are also able to store memory when working on tasks. Working with AI Agents can also include Human in the loop, whereby human can interrupt in the middle of the process, and provides judgement in between.
At the end, the AI Agent in the workflow is able to take actions once the task is completed.
Models(LLM)
Agents are actually powered by Models. Basically, the model is the core engine that runs the Agentic AI. It is able to predict, perform reasoning, summarization, tool calling, planning, and more.
And yes, as you are guessing right now, the models in this context are either:
- ChatGPT GPT-4, GPT-4o etc
- Claude Sonnet 4, 4.5
- Mistral Instruct 7b
- Perplexity
- etc
Usually, an Agentic AI frameworks nowadays provide the flexibility to choose which model we want to include in the workflow. It depends on the workflow use cases and requirements. The model choices play a big role in balancing the factors such as reasoning, quality, latency, cost and others. As of myself, I mainly use models from AWS Bedrock and DeepSeek. For DeepSeek, it provides the freedom to only top up once and use it until the wallet amount runs out.
Models work with tokens, and the real cost comes down to how many tokens are processed and how much each token costs. Every prompt you send and every response you receive consumes tokens, which is why understanding token usage is critical when designing efficient AI agents.
Messages & Prompting
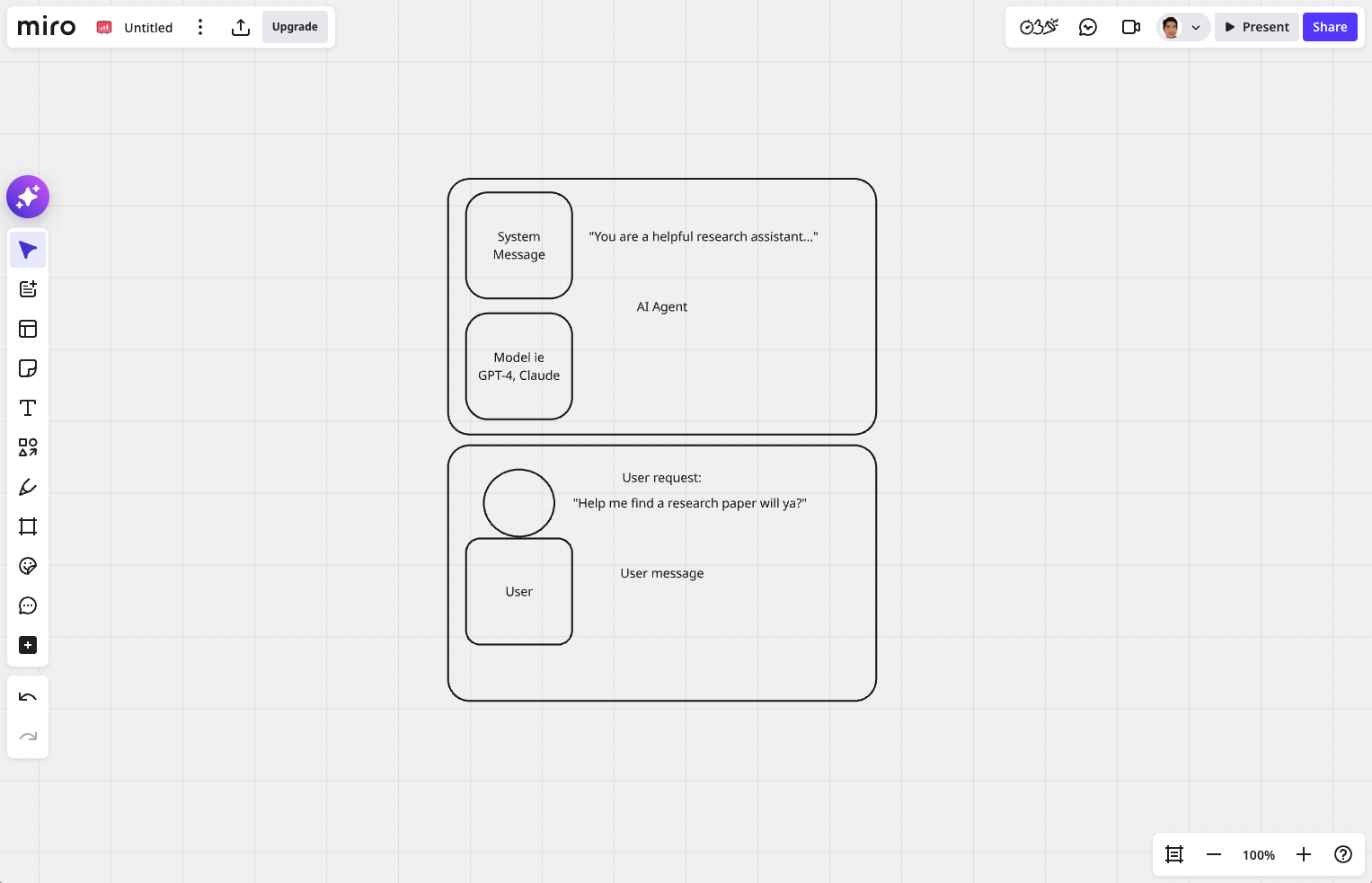
System Message
For System Message, you can think of it as defining the roles for your AI Agents. You can set the requirements for the model to act accordingly. The System Message usually are in form of plain text, mentioning explicitly on what the expectations from the model. For instance:
You are a helpful research assistant. Your job is to help provide research papers regarding the topic of Agentic AI Do not make up any information. Only take the research paper from the authoritative source. Be concise and accurate. Provide the answer in the following format: Title: <Title> Author: <Author> Published Date: <Published Date> Summary: <Summary> Link: <Link>
A good System Message, that easier for the model to understand should have the:
- Clear identity of the AI Agent’s role, or persona
- Task and scope definitions
- Define the tone of the model to response with
- Example of the output
- Guard it with limitations
User Message
User Message is the external request sent to the AI Agent, instructing it to perform specific tasks. It represents a normal human request such as question, command or instruction. It is the trigger of AI Agent to start performing a task.
While it may look simple on the surface, the user message is interpreted in the context of system instructions, memory, and available tools, all of which shape how the agent understands intent and decides what actions to take. For example:
Help me find a research paper on "RAG". Provides me the title, authors, and the links.
Below is the simple diagram on for System Message and User Message.
Tokens
Tokens are like the currency in the LLM world, both output and input. Input is the accumulation of System Message and User Message, being tokenized and passed to LLM, while output is the response back from LLM. The System Message and User Message sentences are combined together and chunked it to tokens. Token is not equal to number of words. For ChatGPT, it provides a tokenizer websites whereby you can see how much tokens are being used before and after passing it to the model to be processed.
Token counts matter because the cost per LLM call depends on the tokens themselves. The more tokens passed, the costly it will be per LLM call. Besides, for each context window, there is a token limit, hence providing too many tokens will cause incorrect responses.
For this matter, I explain it in more details in this article:
Article or token: https://www.notion.so/Token-The-hidden-currency-behind-LLMs-2d2dd4149dba807face4fb83f66cb23b?source=copy_link
Context Window
Context window refers to the maximum amount of information, measured in tokens, that is passed to the model. This includes System Message, User Message, History, Retrieved Memory, Tools etc.
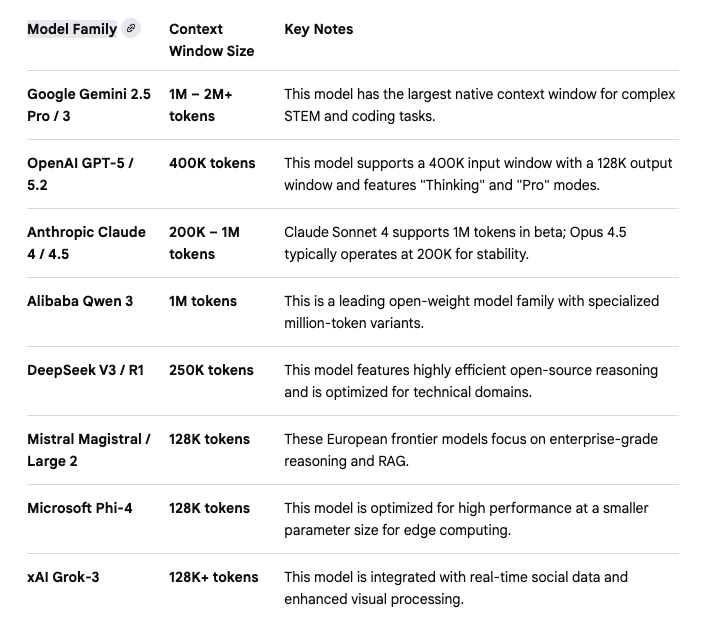
Each model has a limited context window, but the context window is usually pretty wide and models are mostly able to handle quite a huge number of tokens. Based on this table provided by Gemini(hopefully not hallucinating 😅), most popular models able to handle huge number of tokens, so nothing much to worry about.
Sampling Controls
1) Temperature
Temperature is the term used in ML or AI in order to control the diversity and creativity of the model. In certain cases, we might need to adjust the model’s capability according to the business rules. Some needs the model to be more creative in writing, answering and creating creative contents, but some needs the model to be more deterministic.
This are controlled via the temperature variable. The control is from 0 to 1 . The higher the number, the more diverse and creative the model will act.
0.0→ very deterministic0.9→ more creative and diverse
2) Top-P
Top-P is known as Nucleus Sampling. It is a setting to control the randomness of the model’s response. Instead of looking at the thousands of possible words the AI could say next, Top-P setting tells the model to only focus on a small "nucleus" of the most likely words that together add up to a certain probability percentage. The setting are mostly on sentence completion.
Imagine a sentence "The cat sits on the…". The model will calculate and predict the probability for the next incoming words.
- Mat? probably 40%
- Floor? probably 30%
- Chair? probably 15%
- Pizza? highly unlikely, probably 1%.
- etc
If the Top-P is set to 0.85, the model will keeps adding up the most likely words until it hits the ceiling, which is 85%.
- Mat(40%) + Floor(30%) = 70% (Not there yet)
- Mat(40%) + Floor(30%) + Chair(15%) = 85% (Stop now!)
Top-P is just an optional setting. Most LLM comes with default Top-P of 1, which is 100%, so the nucleus setting for most popular models nowadays includes the entire probability mass, allowing it to consider every possible next words.
3) Top-K
Top-K is often considered as the blunt instrument of sampling. It differs with Top-P. While Top-P is percentage based filter, Top-K is fixed count filter. To avoid misinformation, I will quote the definition from this article from DataForest AI.
Top-k sampling is a method used in natural language processing (NLP) and machine learning for generating text by sampling from a restricted subset of the vocabulary. In contrast to greedy or deterministic approaches, top-k sampling introduces controlled randomness, selecting the next word in a sequence from the top k most probable candidates, rather than from the entire distribution. This method helps to balance between diversity and coherence, making it suitable for applications where variation in generated text is desirable without deviating excessively from context. Top-k sampling is particularly valuable in text generation tasks like conversational AI, storytelling, and dialogue systems.
This Top-K topic is quite high level, hence no need to go through deeper.
4) Frequency Penalty
So, we knew that model able to generate new contents based on the requirements right? Hence, Frequency Penalty is the one guiding the contents output. It is a setting to prevents model from becoming too repetitive by penalizing the words(or tokens) based on how many times they already being used before.
The model tracks the count of every token it generates. If a token has already appeared multiple times, its probability of being selected again is reduced.
-
The "Cumulative" Rule: Unlike other settings, the penalty for a specific word grows stronger every time it is used.
-
Formula: Each time a word appears, its "score" (logit) is lowered by
$$
Penalty Value × Count
$$
Most of models use this Range and Impact standards
0.0: No penalty applied. The model can repeat itself as many times as it wants if it deems to.0.1 to 2.0: These decrease repetition. High values (1.0+) force the model to find synonyms, which increases lexical diversity but can sometimes make the text sound unnatural if pushed too far.-2.0 to -0.1: These actually needs repetition. This is rarely used but can be helpful for tasks like writing poetry with a specific refrain or repetitive technical documentation.
Reference from Vellum AI: https://www.vellum.ai/llm-parameters/frequency-penalty?utm_source=google&utm_medium=organic
5) Presence Penalty
Differs from Frequency Penalty, Presence Penalty is a setting to set the new topics in incoming chats. Presence Penalty doesn't penalty the repetitive words, instead applied a flat-rate penalty as soon as a word appeared once.
The Presence Penalty is a binary "tax". It doesn't care if you've said a word once or fifty times; it only checks if the word has "present" in the context text so far.
The logic is, once a token is used, its probability of appearing again is lowered, and the goal is to make the model move on to different ideas, instead of staying on the same subject.
Similar to Frequency Penalty, the Range and Impact standards for most LLM nowadays are:
0.0: No preference for new topics.0.1 to 0.5: Subtle encouragement to be more "talkative" and varied without losing the plot.1.0 to 2.0: Strong pressure to bring up new concepts. At very high levels, this can cause the AI to become erratic or change the subject too abruptly.
Presence vs. Frequency: The "2026 Rule of Thumb"
To remember the difference, think of them as different types of "boring" speech:
- Frequency Penalty stops a "Stutter." It prevents the AI from saying "I am very, very, very, very happy" by penalizing the word "very" more and more each time.
- Presence Penalty stops a "Boring conversation." It prevents the AI from staying on one point for too long. If the AI has already talked about "Safety," the penalty makes it more likely to move on to "Performance" or "Cost."
Agent capabilities
1) Tools calling
Tools in Agentic AI refer to the ability of AI Agents to call external functionality outside of their bounds. For example, the AI Agents can make:
- API calls
- Database query
- Run code snippet
- Search logs
- Perform action
Each AI Agent can have multiple tools attached. Upon execution, the AI Agent will select when to use the tools, based on the descriptions.
These tools can be setup in the workflow by providing the tools details and instruction for it to use in the System Message. Similar to the previous topic, each LLM call that using tools are implementing the token method. Hence, each tool use is actually an LLM call that works on running the tool's functionality, and each of these calls will incur a cost.
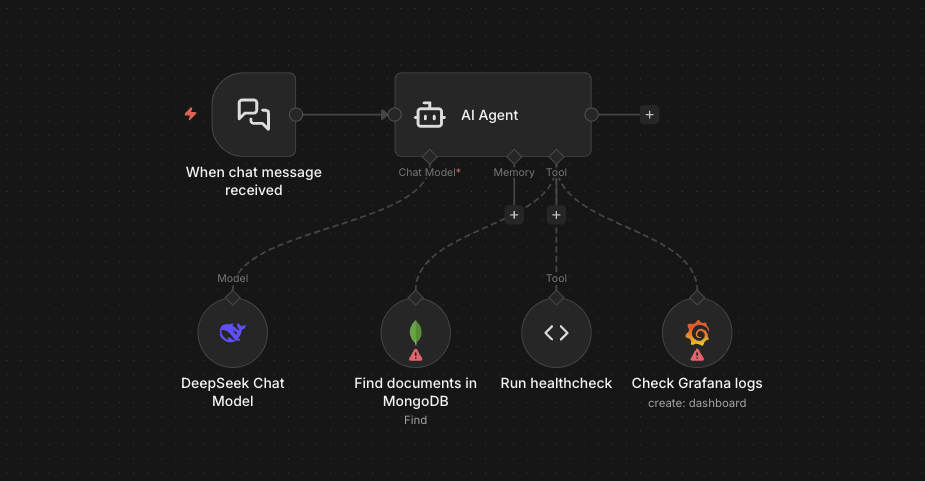
Below is the example of an AI Agent, made with n8n, that attached to tools for
- Finding documents in MongoDB
- Run health checks
- Check the logs from Grafana
3 different sets of tools mean 3 different set of LLM calls made by the AI Agent.
2) Streaming
Most LLM chats implement Streaming. Streaming basically model response with tokens and the response displayed real-time, as they are being generated instead of waiting for the full response. The purpose of Streaming is to enable real-time updates, improve the latency per request, and look conversational from the chat UI perspective.
3) Structured output
LLMs provide answers in sentences, whereby the sentences are able to be perceived and understood by humans. But in certain cases, we don't want the output to be in sentences, but instead in JSON, to ease the parsing process later on when the graph continues.
For example, from this sentence response.
These are the top 5 articles about RAG: 1 Title. RAG 101 URL: https://www.example.com/1 2. How to do RAG in 2026 URL: https://www.example.com/2 3. RAG examples URL: https://www.example.com/3 4. The complete guides on RAG URL: https://www.example.com/4 5. RAG, Vector DBs, and LLMs: A Comprehensive Guide URL: https://www.example.com/5
We can rewrite the output with Structured Output to only provides the result in this manner.
{ "articles": [ { "id": 1, "title": "RAG 101", "url": "https://www.example.com/1" }, { "id": 2, "title": "How to do RAG in 2026", "url": "https://www.example.com/2" }, { "id": 3, "title": "RAG examples", "url": "https://www.example.com/3" }, { "id": 4, "title": "The complete guides on RAG", "url": "https://www.example.com/4" }, { "id": 5, "title": "RAG, Vector DBs, and LLMs: A Comprehensive Guide", "url": "https://www.example.com/5" } ] }
Memory
1) Short term memory
Short-term memory refers to an AI Agent's memory to remember past chat histories in order to respond to upcoming questions correctly within its context. Short-term memory is stored in prompt and limited by token window.
2) Long term memory
Long-term memory is persistent data stored outside of the prompt that is useful for AI Agent processes. These are usually stored in:
- Vector databases
- Knowledge bases
Long-term memory is usually used and retrieved when it is relevant.
Safety & Security control
Guardrails
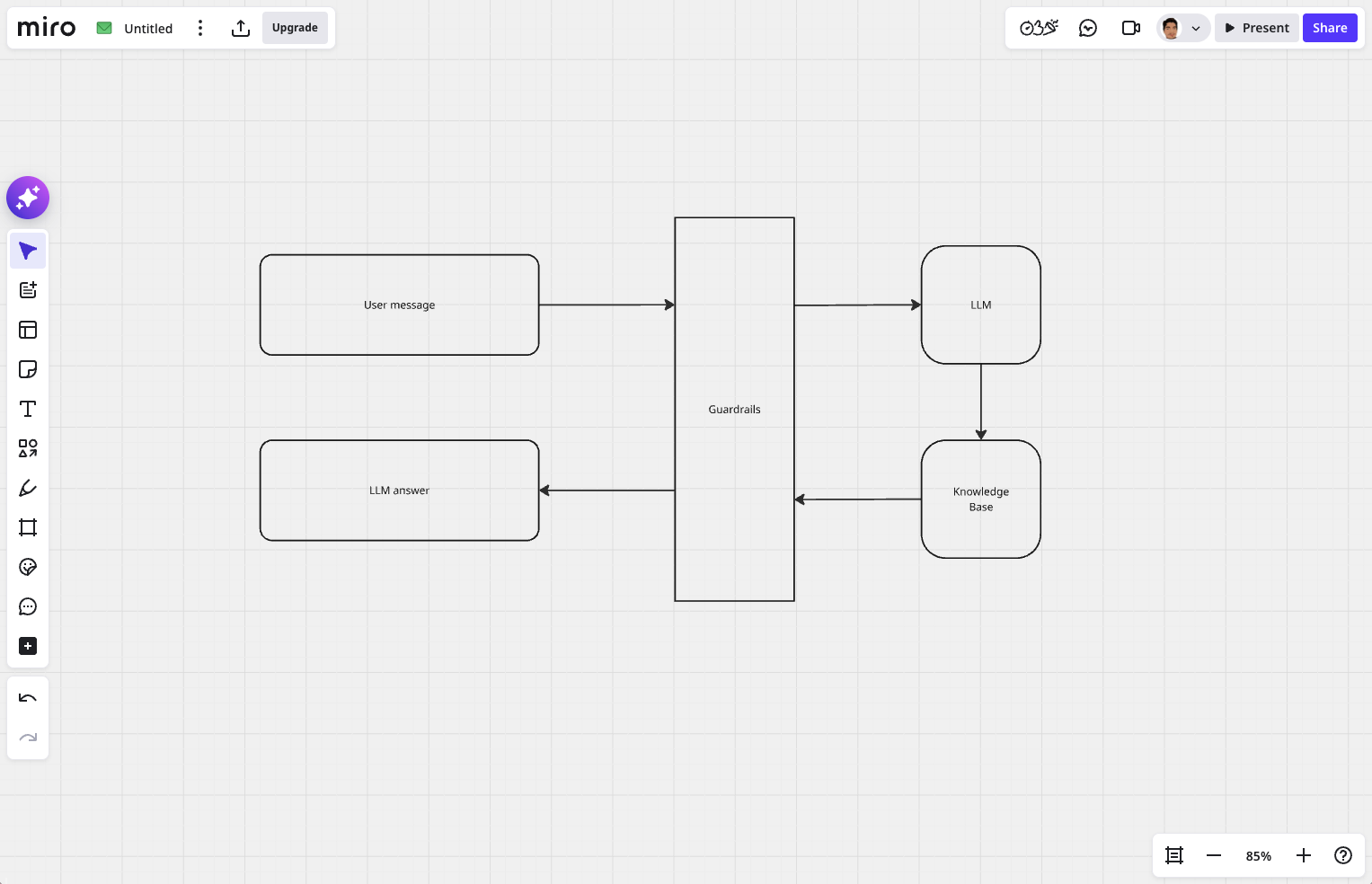
Guardrails are a set of rules and validations provided to the LLM. This set of rules can be in terms of content filtering, schema validations, business rules guidelines and safety checks.
Suppose you have an AI Agent that acts as Customer Service for a company that sells pastries. This AI Agent's job scope is to answer questions about the shop’s menu, list pastries available in the shop, and handle customers’ table bookings. From this, we can foresee incoming issues whereby users will ask questions unrelated to pastries. Here, Guardrails come into place. Guardrails can be attached to the AI Agent to not entertain any questions that are out of scope.
Human in the Loop
Human in the loop (HITL) is basically an interruption during a workflow executions whereby it needs affirmation from human. Human will intervene in between to review, and either approve or reject. Most of the time, HITL is used for high-risk actions and decisions.
By introducing human oversight at key decision points, HITL increases reliability, reduces unintended consequences, and builds confidence in agent-driven systems, especially as they operate in complex and uncertain real-world environments.
Today’s AI Agents are still learning how to listen, remember, and act much like apprentices finding their way, but the foundations we put in place now will define how capable and trustworthy they become tomorrow. Every token budget, every system message, every guardrail, and every human checkpoint is a small design decision that quietly shapes an agent’s behavior in the real world. As models grow stronger and frameworks more flexible, the future of agents will not be defined by raw intelligence alone, but by how thoughtfully we design their workflows, memories, and boundaries.
Those who understand these fundamentals today will be the ones building agents that don’t just respond, but truly assist, collaborate, and earn trust in the systems of the future.
Happy crafting 😄.
Written with love by Arif Mustaffa
Back to blog page