
Token, this mystic word comes a lot in this AI and LLMs era. For us humans, conversations are built from sentences and ideas that flow naturally from one to another, bit by bit, combinations of words makes into a complete sentence, and complete sentences makes it clear to the audiences. But for large language models(LLMs), those same sentences are first broken down into tokens the fundamental units that shape how a chatbot reads, understands, and responds.
LLMs interpret every message through tokens, transforming human language into a format machines can reason with. It operate on tokens, converting each prompt and reply into smaller units that define context, memory, and cost.
What Is a Token, Really?
Tokens are the smallest meaningful units an LLM understands. Let’s take an example, a word happy . This words might be 1 word to human, but for LLM, it got break down it 1 or 2 token. Most of the times, token have around 4 characters. So, for Happy day!, depends on the LLM, most of will count as 2 tokens, some 3.
# Conceptually like this "Happy" -> 1 token "day" -> 1 token "!" -> 1 token
For just happy word, it could be broken down it multiple and variety of subwords. For example, un and happy or happi and ness. The punctuations and spaces are also takes into considerations as well. In short, “Happy day!” is not exactly means 2 tokens.
How Tokenization Affects Chatbot Conversations
In shorts, every chat messages are broken into tokens before the model “thinks”. OpenAI provides how the models tokenizers works. You can view more on this page.
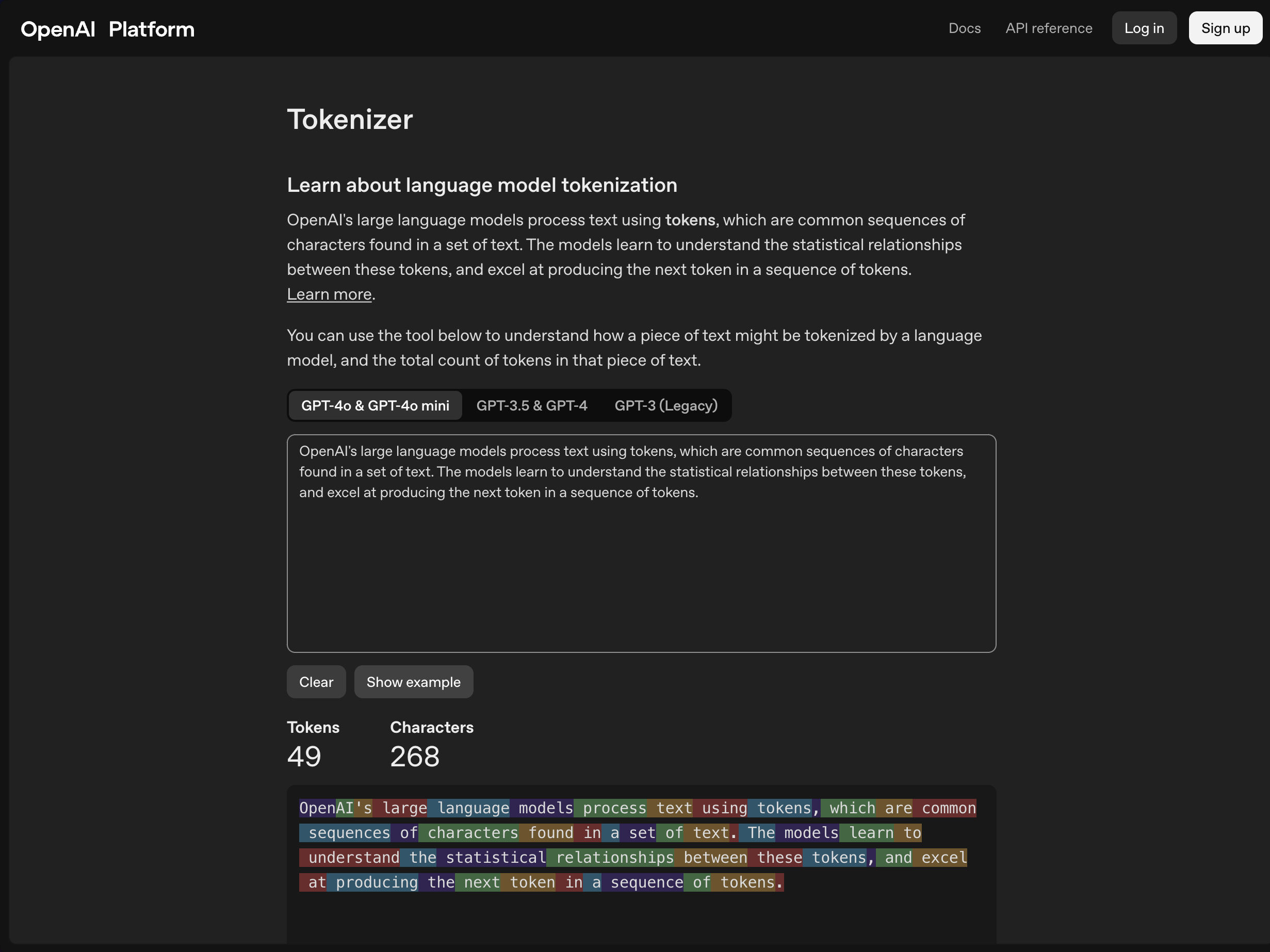
For the sentence:
OpenAI's large language models process text using tokens, which are common sequences of characters found in a set of text. The models learn to understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens.
GPT-4o & GPT-4o mini detects 268 total characters and later on, tokenize the characters into tokens. There are 49 tokens detected. Hence, in a chat model, if this is the chat prompt provided, basically user provides 49 tokens to LLM and based on it, it will response back an answer. Those answer albeit readable and understandable by humans, it also applies the token concepts. So there are input and output token concepts.
Tokens = Cost (and Performance)
Tokens can affect the cost of LLMs. More token means more semantic meanings and tasks or process need to be covered by LLMs. This explains why verbose prompts are expensive. A complete and concise instructions perform better for all LLMs and it provides practical impact on production chatbots. By provides a good prompts, the LLMs able to translate the prompts, understand the meaning, and works on the tasks or question properly. This comes into a terminology in AI which is “prompt engineering”. I will cover this topic on different article.
In conclusions, prompting concisely plays a big role when interacting with LLMs chatbot. Those prompts will be converted to tokens, hence passed into LLMs for processing. A concise prompt can impact the response. Ensure that during prompting, only provides the context needed by the LLMs, not unrelated sentence, which can affect the answer.
Related article:
- OpenAI tokenizer: https://platform.openai.com/tokenizer
Happy prompting 😎.
Written with love by Arif Mustaffa
Back to blog page